Clean 🧼 Architecture 🛠 At Hyper ⚡️
April 26, 2022 - 7 min readWith the beta launch of hyper cloud, I want to share a little bit about how hyper itself works under the hood, and how we leveraged the architecture to build tools that we use to build hyper, with hyper.
We are currently offering hyper cloud tours and a free Architecture Consultation, If you think we could help you build your next great project, let us know!
Clean Architecture 🧼🛠
At Hyper, we embrace the Clean Architecture approach to building software. This means separating side effects from business logic and working hard to keep business logic separated from other components.
What is business logic? It’s your secret sauce; the data models that may interact with each other, and the rules that govern how those models interact with each other. It is not a database, and it is not a frontend framework. Those pieces are side effects that tie into your business logic. As Robert C. Martin, author of Clean Architecture put it:
there is nothing architecturally significant about arranging data in rows within tables
 Source: https://en.wikipedia.org/wiki/Business_logic
Source: https://en.wikipedia.org/wiki/Business_logic
I won’t go into great detail here, there are tons of material on this topic. We encourage teams to build software using the tenants of “Clean Architecture” and we’ve built hyper to encourage doing just that. And not only do we encourage teams to build software using the tenants of Clean Architecture, but this is also how we architected hyper, internally.
Under The Hood 🚘
Hyper is built using a ”Ports and Adapters” approach.
The general idea with Ports and Adapters is that the business logic layer defines the models and rules on how they interact with each other, and also a set of consumer-agnostic entry and exit points to and from the business layer. These entry and exit points are called “Ports”. All components external to the business layer, interact by way and are interacted with, the Ports. A Port defines an api but knows nothing about the mechanism or the impetus. Those two things are an Adapter’s job.
Adapters perform the actual communication between external actors and the business layer. There are generally two types of Adapters: “Driving Adapters” and “Driven Adapters”.
A driving adapter calls into the business layer, by way of a Port. The driving adapters can generally be thought of as the “presentation layer”. It could be a web application, a desktop application, a CLI, anything that initiates some action on the business domain.
A driven adapter is called by the business layer, to interact with some backend tool, ie. a database, storage bucket, cache, etc. The business layer calls into the driven adapter by way of the Port. Driven adapters implement the Port defined by the business layer.
So the flow generally looks like
Driving Adapter <--> Port <--> Business Layer <--> Port <--> Driven Adapter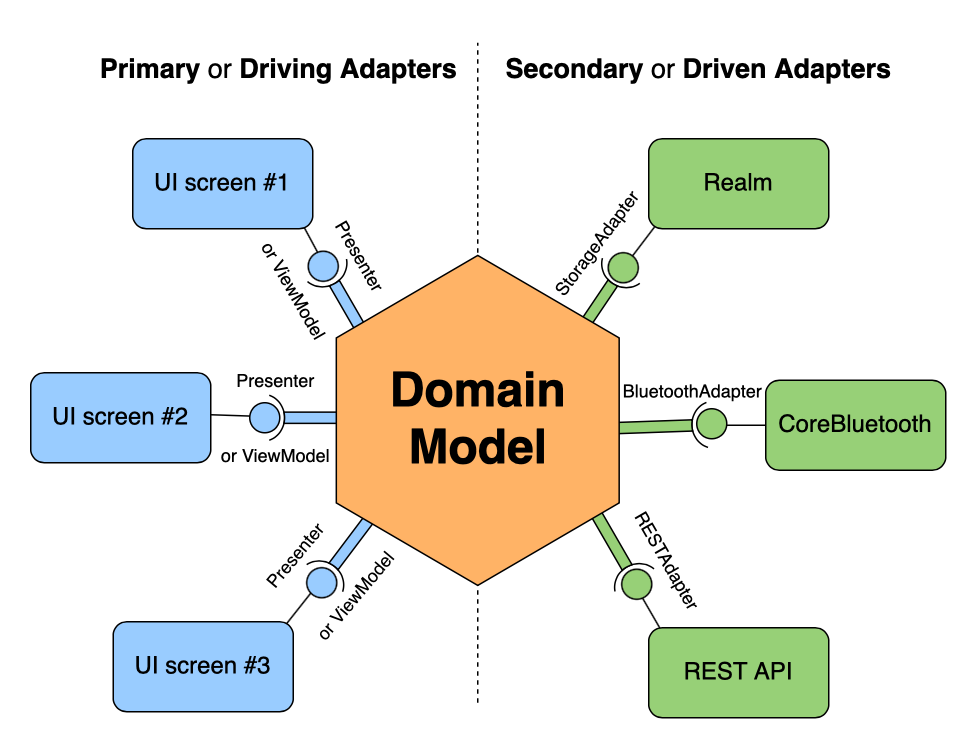
Source: https://betterprogramming.pub/hexagonal-architecture-for-ios-part-1-600441c186b7
Benefits
Because the business layer enforces the Ports, and all external interactions with external components happens through the Ports, the business layer is encapsulated. The benefits of this for the system cannot be overstated.
It means the business layer, the models and the rules governing them, can be developed before choosing things like a database, or a frontend framework. Better yet, the business layer can be tested before choosing any of those things. Covering business logic almost entirely with unit tests is a boon for confidence in the system.
When building software, a decision is a set of constraints, and ideally the pros of accepting those constraints outweigh the cons. So we ought to defer accepting constraints until we have as much information as possible to inform that decision. Clean Architecture enables us to do just that.
It also allows for the separation of concerns. Each tier of the architecture can change without requiring changes in the other tiers. This is important because some tiers are more volatile than others; typically the UI of an application changes faster than business rules for example.
The only time we must touch multiple tiers is if a Port is changed. And that is usually a find and replace
Hyper Clean Architecture Lingua Franca 📚
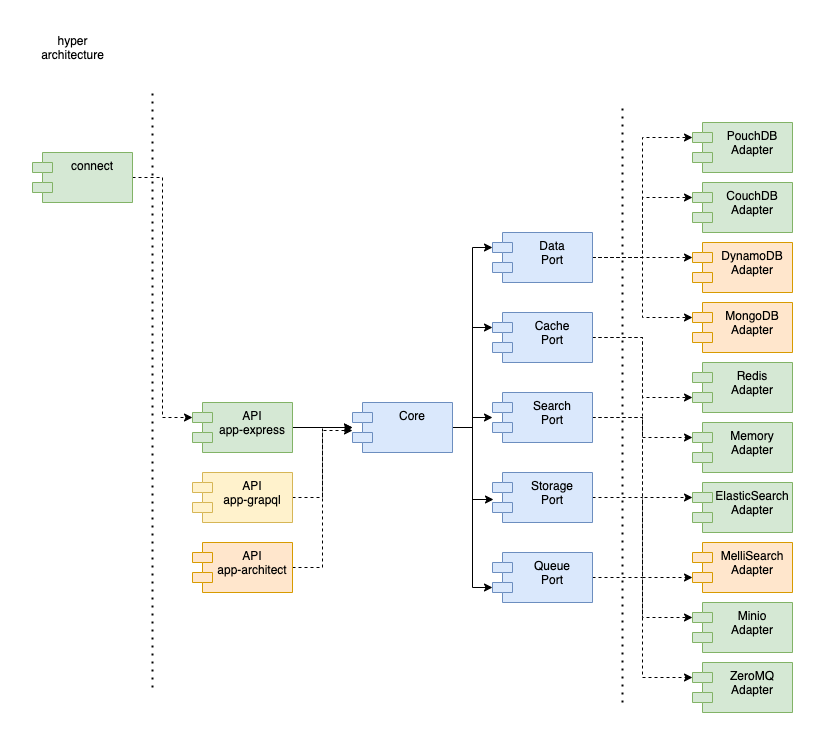
Hyper Apps 🎮
The Driving Adapters in the Hyper Service Framework are called “Apps” or “Apis”. We currently have two Apps available shown here. The GraphQL app will need to be overhauled eventually, but the Opine app is up to date and provides a RESTful api.
In the future, we would like to see more app offerings. A CLI app, a GRPC app, we’ve even discussed a Service Worker app, so that Hyper could be run entirely in the browser, on a Service Worker 😎.
Hyper Core 🪨
The business layer in Hyper is called core which contains all of the business logic and enforces each Port. Core also defines the Port that a Hyper App calls.
Hyper Ports 🔌
There are multiple Ports defined in the Hyper Service Framework. You can see them all here.
Hyper Adapters 🛠
The Driven Adapters in the Hyper Service Framework are simply called “Adapters”. You can see many of them here. Each adapter implements a Port api and does the heavy lifting of communicating with an underlying component.
Hyper Services
A Hyper Service is combination of the components described above:
- A Hyper App
- Hyper Core
- An Adapter Port
- A Hyper Adapter
For example, a Hyper Data Service might be:
RESTful api -> Core -> Data Port -> CouchDB Adapter
// or
GraphQL api -> Core -> Data Port -> Postgres Adapter
// or
CLI -> Core -> Data Port -> DynamoDB AdapterA Hyper Cache Service might be:
GRPC api -> Core -> Cache Port -> Redis Adapter
// or
GraphQL api -> Core -> Cache Port -> Sqlite Adapter
// or
CLI -> Core -> Cache Port -> FlatFile AdapterA Hyper Search Service might:
GRPC api -> Core -> Search Port -> Elasticsearch Adapter
// or
RESTful api -> Core -> Search Port -> Minisearch Adapter
// or
CLI -> Core -> Search Port -> Algolia AdapterI hope you’re noticing something:
Adapters and Apps are interchangeable. This is how we can test our business layer without choosing a database, for example. We just mock the Adapter that communicates with the database.
This also means we can run the Hyper Service Framework using a set of “local development” adapters.
Hyper Nano 🍷
Hyper Nano is the compiled Hyper Service Framework using a set of “local development” adapters. It’s the same Hyper RESTful app, and the same Hyper Core, but with a set of adapters that allow it to run locally sandboxed, and simple to quickly spin up and then blow away.
- data (powered by PouchDB)
- cache (powered by Sqlite)
- storage (powered by your local file system)
- search (powered by Sqlite and Minisearch)
- queue (powered by DnDB and an in-memory queue)
Hyper Nano is great for development or sandboxed short-lived environments ie. GitHub Workspaces or GitPod.
Hyper Nano has some other features that we will cover in another blog post.
At hyper, we use Hyper Nano to develop hyper products. When building hyper cloud, we simply spin up a Gitpod Workspace, which installs our dependencies, starts Hyper Nano, and bootstraps our services. The result is a completely sandboxed local development environment in Cloud 😎 ☁️⚡️. Yes, we use hyper to build hyper.
Then in deployed environments, we use the Hyper Service Framework, but with actual Adapters to actual external services. Our interactions with Hyper does not change between Hyper Cloud and Hyper Nano
Conclusion
We try to practice what we preach, we dogfood practically everything we build, and hopefully, this provides some insights on how Hyper works internally and why you might consider trying Clean Architecture and Hyper.
We are currently offering hyper cloud tours and a free Architecture Consultation, If you think we could help you build your next great project, let us know!
Acknowledgements
- https://en.wikipedia.org/wiki/Business_logic for the 3 tier architecture graphic
- Oleksandr Stepanov’s awesome post on Hexagonal Architecture, which provides some great visualizations of the architecture